Ksama Arora
Managed Online vs Batch Endpoints for Model Deployment in Azure
Jan 07, 2025In the ever-evolving field of artificial intelligence, Azure Machine Learning (Azure ML) simplifies the deployment and consumption of machine learning models. This guide provides an overview of deploying models to managed online endpoints (real-time) and batch endpoints.
Contents
- What is a Managed Online Endpoint?
- Deploying Models to Managed Online Endpoints
- Deploying Models to Batch Endpoints
Deploying Models to Managed Online Endpoints
What is a Managed Online Endpoint?
An HTTPS endpoint that:
- Accepts input data for inferencing.
- Returns a response (almost) immediately by invoking a scoring script hosted on the endpoint.
Types of online endpoints:
- Managed Online Endpoints: Azure ML manages the infrastructure.
- Kubernetes Online Endpoints: You manage the infrastructure (Kubernetes cluster).
To deploy a model to a managed online endpoint, you need:
- Model assets: E.g., a pickle file or a registered model in Azure ML Workspace.
- Scoring script: Loads the model and generates predictions.
- Environment: Specifies required packages.
- Compute configuration: Defines VM size and scale settings.
Blue/Green Deployment
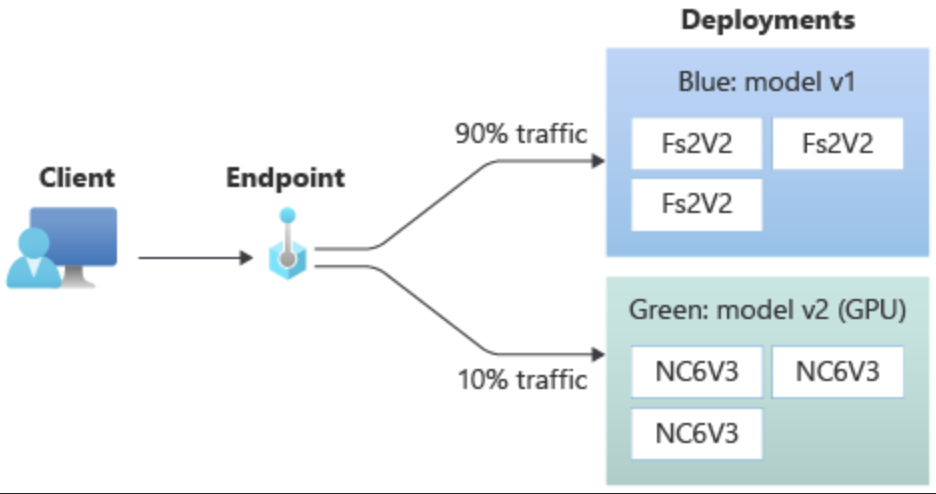
Blue/green deployment allows multiple models to be deployed to an endpoint. Traffic can be distributed between deployments for testing and transitioning:
- Example: 90% of traffic to a blue deployment, 10% to a green deployment.
- Adjust traffic dynamically based on model performance.
Deploying MLFlow Models to Managed Online Endpoints
When deploying MLFlow models:
- Scoring scripts and environments are automatically generated.
Code Example
from azure.ai.ml.entities import Model, ManagedOnlineDeployment
from azure.ai.ml.constants import AssetTypes
# Define the model
model = Model(
path="./model",
type=AssetTypes.MLFLOW_MODEL,
description="MLFlow model example",
)
# Create a deployment
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name="endpoint-example",
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
Traffic Management
Direct traffic to specific deployments:
# Allocate 100% traffic to blue deployment
endpoint.traffic = {"blue": 100}
ml_client.begin_create_or_update(endpoint).result()
Switch between deployments:
# Allocate 25% traffic to blue and 75% to green deployment
endpoint.traffic = {"blue": 25, "green": 75}
ml_client.begin_create_or_update(endpoint).result()
Deleting an Endpoint
ml_client.online_endpoints.begin_delete(name="endpoint-example")
Deploying Non-MLFlow Models to Managed Online Endpoints
Requirements
- Model assets (local or registered).
- A custom scoring script.
- Environment with necessary dependencies.
- Compute configuration.
Example Scoring Script
import json
import joblib
import numpy as np
import os
def init():
global model
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), 'model.pkl')
model = joblib.load(model_path)
def run(raw_data):
data = np.array(json.loads(raw_data)['data'])
predictions = model.predict(data)
return predictions.tolist()
Creating an Environment
Using a Conda YAML file:
name: basic-env-cpu
channels:
- conda-forge
dependencies:
- python=3.7
- scikit-learn
- pandas
- numpy
- matplotlib
from azure.ai.ml.entities import Environment
env = Environment(
image="mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
conda_file="./src/conda.yml",
name="deployment-environment",
description="Custom environment with Conda dependencies",
)
ml_client.environments.create_or_update(env)
Creating a Deployment
from azure.ai.ml.entities import ManagedOnlineDeployment, CodeConfiguration
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name="endpoint-example",
model=model,
environment="deployment-environment",
code_configuration=CodeConfiguration(
code="./src", scoring_script="score.py"
),
instance_type="Standard_DS2_v2",
instance_count=1,
)
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
Deploying Models to Batch Endpoints
What is a Batch Endpoint?
- Designed for asynchronous and high-latency tasks.
- Ideal for large, time-consuming jobs (e.g., hourly, daily, or weekly schedules).
Creating a Batch Endpoint
from azure.ai.ml.entities import BatchEndpoint
endpoint = BatchEndpoint(
name="endpoint-example",
description="Batch endpoint example",
)
ml_client.batch_endpoints.begin_create_or_update(endpoint)
Deploying MLFlow Models to Batch Endpoints
Register an MLFlow Model
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
model = ml_client.models.create_or_update(
Model(name="mlflow-model", path="./model", type=AssetTypes.MLFLOW_MODEL)
)
Deploy the Model
from azure.ai.ml.entities import BatchDeployment, BatchRetrySettings
from azure.ai.ml.constants import BatchDeploymentOutputAction
deployment = BatchDeployment(
name="forecast-mlflow",
endpoint_name=endpoint.name,
model=model,
compute="aml-cluster",
instance_count=2,
max_concurrency_per_instance=2,
mini_batch_size=2,
output_action=BatchDeploymentOutputAction.APPEND_ROW,
output_file_name="predictions.csv",
retry_settings=BatchRetrySettings(max_retries=3, timeout=300),
)
ml_client.batch_deployments.begin_create_or_update(deployment)
Deploying a Custom Model to a Batch Endpoint Without Using MLflow Model Format
To deploy a custom model, you must create:
(A) Scoring Script
The scoring script must include two functions:
- init(): Called once at the beginning of the process. Use this for costly or common preparations like loading the model.
- run(): Called for each mini-batch to perform the scoring. The
runmethod should return a pandas DataFrame or array/list.
import os
import mlflow
import pandas as pd
def init():
global model # Make assets available for scoring
# Get the path to the registered model file and load it
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = mlflow.pyfunc.load_model(model_path)
def run(mini_batch):
print(f"run method start: {__file__}, run({len(mini_batch)} files)")
result_list = []
for file_path in mini_batch:
data = pd.read_csv(file_path)
pred = model.predict(data)
df = pd.DataFrame(pred, columns=["predictions"])
df["file"] = os.path.basename(file_path)
result_list.extend(df.values)
return result_list
(B) Create an Environment
You can create an environment using a Docker image with Conda dependencies or a Dockerfile.
Conda YML File Example:
name: basic-env-cpu
channels:
- conda-forge
dependencies:
- python=3.8
- pandas
- pip
- pip:
- azureml-core
- mlflow
from azure.ai.ml.entities import Environment
env = Environment(
image="mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
conda_file="./src/conda-env.yml",
name="deployment-environment",
description="Environment created from a Docker image plus Conda environment.",
)
ml_client.environments.create_or_update(env)
(C) Create the Deployment
from azure.ai.ml.entities import BatchDeployment, BatchRetrySettings
from azure.ai.ml.constants import BatchDeploymentOutputAction
deployment = BatchDeployment(
name="forecast-mlflow",
description="A sales forecaster",
endpoint_name=endpoint.name,
model=model,
compute="aml-cluster",
code_path="./code",
scoring_script="score.py",
environment=env,
instance_count=2,
max_concurrency_per_instance=2,
mini_batch_size=2,
output_action=BatchDeploymentOutputAction.APPEND_ROW,
output_file_name="predictions.csv",
retry_settings=BatchRetrySettings(max_retries=3, timeout=300),
logging_level="info",
)
ml_client.batch_deployments.begin_create_or_update(deployment)
This structured approach enables you to deploy and consume models efficiently using Azure ML. Whether you need real-time predictions or large-scale batch processing, Azure ML has you covered.