Ksama Arora
Microsoft Certified: Azure Data Fundamentals (DP-900)
Aug 21, 2024Contents
- Explore core data concepts
- Explore relational data in azure ______________________________
Azure Storage Services:
- Azure Storage Accounts: Umbrella service for Table, File, and Blob storage.
- Azure Blob Storage: Object storage for unstructured data, distributed across machines.
- Azure Tables: Key/value NoSQL store for simpler projects.
- Azure Files: Managed NFS or SMB file-sharing.
- Azure Storage Explorer: Application to explore data in Azure Storage Accounts.
Azure Data Services:
- Azure Synapse Analytics: Unified analytics platform for data warehousing.
- CosmoDB: Fully-managed NoSQL database service with various engines (Tables, Document, Key/Value, Graph).
- Azure Data Lake Store (Gen2): Centralized data repository for large amounts of data.
- Azure Data Analytics: Big Data as a Service (BDaaS), uses U-SQL to return data from Azure Data Lake.
- Azure Data Box: Import/export large datasets via hard drive to/from Azure datacenters.
SQL and Database Services:
- SQL Server on Azure VMs: For migrating SQL workloads with full OS access.
- SQL Managed Instances: Managed SQL Server with broader adaptability for migration.
- Azure SQL: Fully-managed MS SQL databases.
- Azure Databases for Open Source: Managed relational databases (MySQL, PostgreSQL, MariaDB).
- Azure Cache for Redis: In-memory data store for fast data retrieval.
Data Integration and Processing Services:
- Azure Data Studio: Cross-platform IDE for data tasks, similar to SSIS but broader in scope.
- Azure Data Factory: Managed ETL/ELT pipeline builder.
- SQL Server Integration Services (SSIS): Prepares data for SQL workloads via transformation pipelines.
Business Intelligence and Big Data Tools:
- Microsoft Power BI: Business Intelligence tool for dashboards and reports.
- HDInsights: Fully-managed Hadoop service for Big Data transformations.
- Azure Databricks: Apache Spark service for fast ETL jobs, machine learning, and streaming.
- Microsoft Office 365 SharePoint: Shared file system with role-based access control.
Types of Cloud Computing
SaaS:
- Product that is run and managed by the service provider.
- Don’t worry about how the service is maintained.
- It just works and remains available. E.g. PowerBI Office 365
PaaS:
- Focus on deployment and management of your apps.
- Don’t worry about provisioning, configuring or understanding the hardware of OS.
- E.g. HDInsight, Managed SQL, Azure SQL, Cosmos DB
IaaS:
- The basic building blocks of cloud IT.
- Provides access to networking features, computers, and data storage space.
- Don’t worry about IT staff, data centers and hardware.
- E.g. SQL VM, Azure Disks, VMs
Azure Data Roles:
Database Administrator: Configures and maintains a database (e.g., Azure Data services or SQL server).
- Responsibilities:
- Database management
- Manage security, granting user access
- Backups
- Monitors performance
- Common Tools:
- Azure Data Studio
- SQL Server Management Studio
- Azure Portal
- Azure CLI
- Responsibilities:
Data Engineer: Designs and implements data tasks related to the transfer and storage of big data.
- Responsibilities:
- Database pipelines and processes
- Data ingestion and storage
- Prepare data for analytics
- Prepare data for analytical processing
- Common Tools:
- Azure Synapse Studio
- SQL
- Azure CLI
- Responsibilities:
Data Analyst: Analyzes business data to reveal important information.
- Responsibilities:
- Provides insights into the data
- Visual reporting
- Modeling data for analysis
- Combines data for visualization and analysis
- Common Tools:
- Power BI Desktop
- Power BI Portal
- Power BI Services
- Power BI Report Builder
- Responsibilities:
Database Administrator Tools:
- Azure Data Studio:
- Connect to Azure SQL, Azure data warehouse, Postgres SQL, and SQL Server (big data clusters, on-premises).
- Graphical interface for managing on-premises and cloud-based data services.
- Runs on Windows, macOS, and Linux.
- Extensions for automation tasks.
- Possibly a replacement for SSMS (though SSMS is still more mature).
- SQL Server Management Studio (SSMS):
- Tooling for running SQL commands or managing database operations.
- Graphical interface for on-premises and cloud-based services.
- Runs on Windows.
- More mature than Azure Data Studio.
- Azure Portal and CLI:
- Manage SQL database configurations (e.g., create, delete, resize, number of cores).
- Automate tasks with Azure Resource Manager templates (IaC).
Data Engineering Common Tools:
- Azure Synapse Studio:
- Integrated portal for managing Azure Synapse, data ingestion (Azure Data Factory), and Synapse assets (SQL Pools/Spark Pool).
- Knowledge SQL:
- Create databases, tables, views, etc.
- Azure CLI:
- Support operations SQL cmd to connect to Microsoft server.
- Run SQL queries and commands.
- HDInsights:
- Streaming data via Apache Kafka or Apache Spark.
- ELT jobs via HIVE, PIG, Apache Spark.
- Azure Databricks:
- Apache Spark for ELT or streaming jobs to data warehouses or data lakes.
Data Analyst Common Tools:
- Power BI Desktop:
- Standalone application for data visualization.
- Data modeling and connecting to data sources.
- Create interactive reports.
- Power BI Portal/Power BI Services:
- Web UI for creating interactive dashboards.
- Power BI Report Builder:
- Create paginated reports (printable reports).
Explore core data concepts
Different Data Formats
Structured data: fixed schema - all data have same fields or properties - mostly tabular format
Semi-structured data: has some structure, but will allow for some variation between instances - common format for semi-structured data is JavaScript Object Notation (JSON)
Unstructured data - e.g. docs, images, audio and video data and binary files
Common File Formats
Delimited text files
- It is a comma-separated values (CSV) in which fields are separated by commas, and rows are terminated by carriage return/new line
- First line may include field names
- Delimited text is good for structured data that needs to be accessed by a wide range of applications and services in a human-readable format
- E.g.
FirstName,LastName,Email
Joe,Jones,joe@litware.com
Samir,Nadoy,samir@northwind.com
Other common formats:
- Tab-separated values (TSV) and space-delimited: in which tabs or spaces are used to separate fields
- Fixed-width data: in which field is allocated a fixed number of characters
JavaScript Object Notation (JSON)
- It is a format in which hierarchical document schema is used to define data entities (objects) that have multiple attributes
- used for both structured and semi-structured data
- E.g.
// Customer1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
Extensible Markup Language (XML)
- It is a human-readable format
- XML uses tags enclosed in angle-brackets (<../>) to define elements and attributes
- E.g.
<Customers>
<Customer name="Joe" lastName="Jones">
<ContactDetails>
<Contact type="home" number="555 123-1234"/>
<Contact type="email" address="joe@litware.com"/>
</ContactDetails>
</Customer>
<Customer name="Samir" lastName="Nadoy">
<ContactDetails>
<Contact type="email" address="samir@northwind.com"/>
</ContactDetails>
</Customer>
</Customers>
Binary Large Object (BLOB)
- All files are ultimately stored as binary data (1’s and 0’s), but in human-readable formats, bytes of binary data are mapped to printable characters (ASCII or Unicode)
- Common data stored as binary include images, video, audio, and application-specific documents
Optimized file formats:
| Format | Type | Developed By | Key Features |
|---|---|---|---|
| Avro | Row-based format | Apache | Each record has a JSON header describing the structure of the binary data, good for data compression, and minimizes storage and network bandwidth requirements. |
| ORC | Columnar data format | HortonWorks | Optimizes read and write operations in Apache Hive, contains stripes of data for columns, includes statistical info (count, sum, max, min) in footers. |
| Parquet | Columnar data format | Cloudera and Twitter | Contains row groups with column data, includes metadata for efficient retrieval of specified columns, specializes in nested data types, supports efficient compression. |
Databases
Relational Databases: commonly used to store and query structured data - data stored in tables that represent entities, such as customers, products, or sales orders. Each instance of an entity is assigned a primary key that uniquely identifies it - and these keys are used to reference the entity instance in other tables.
- The tables are managed and queried using Structured Query Language (SQL), which is based on an ANSI standard, so it’s similar across multiple database systems

Non-Relational Databases (NoSQL database): are data management systems that don’t apply a relational schema to data.
Key-value databases: each record consists of unique key and associated value, which can be in any format
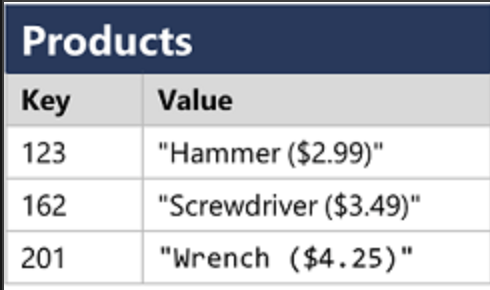
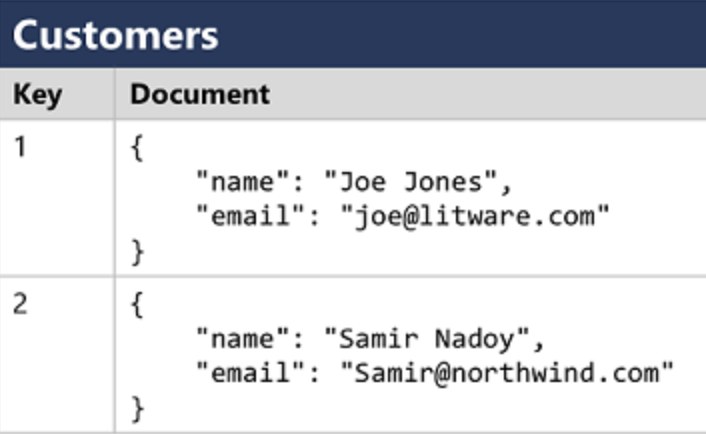
Document databases: specific form of key-value database in which the value is a JSON document (which the system is optimized to parse and query)
Column family databases: tabular data comprising of rows and columns, but can divide columns into groups known as column-families (holds a set of columns that are logically related together)

Graph Databases: which stores entities as nodes with links to define relationships between them
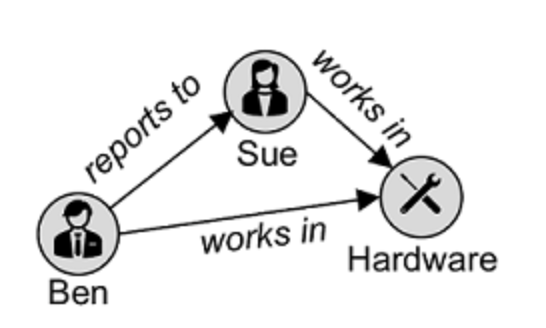
Transactional Data Processing
Transactional systems are high-volume systems designed to process data quickly. The work performed by these systems is known as Online Transactional Processing (OLTP).
OLTP solutions rely on database systems optimized for both read and write operations to support transactional workloads. These workloads involve creating, retrieving, updating, and deleting (CRUD) operations on data records.
OLTP systems adhere to the ACID principles to ensure reliable transaction processing:
| ACID Principle | Description | Example |
|---|---|---|
| Atomicity | Each transaction is treated as a single unit that either fully succeeds or fully fails. | A transaction involving debiting funds from one account and crediting the same amount to another must complete both actions or neither. |
| Consistency | Transactions transition the database from one valid state to another. | The final state of a transaction must accurately reflect the transfer of funds between accounts. |
| Isolation | Concurrent transactions do not interfere with each other and result in a consistent database state. | While funds are being transferred, another transaction checking the balance must show consistent results, without mixing pre- and post-transfer states. |
| Durability | Once a transaction is committed, it remains so, even in the event of a system failure. | After the account transfer is complete, the updated balances are preserved even if the database system is turned off and back on. |
Analytical Data Processing
- Operational Data Extraction: Data is extracted, transformed, and loaded (ETL) into a data lake for analysis.
- Schema Locking: Data is organized into schemas of tables, typically in a Spark-based data lakehouse with tabular abstractions over files in the data lake, or in a data warehouse with a fully relational SQL engine.
- OLAP Models: Data in the data warehouse may be aggregated and loaded into an online analytical processing (OLAP) model, or cube. Aggregated numeric values (measures) from fact tables are calculated for intersections of dimensions from dimension tables. For example, sales revenue might be totaled by date, customer, and product.
- Querying and Reporting: Data in the data lake, data warehouse, and analytical model can be queried to produce reports, visualizations, and dashboards.
Types of Data Storage:
- Data Lakes: Storage for unstructured data for analytical workloads.
- Data Warehouses: Storage for data in a relational schema optimized for read operations.
- Data Lakehouses: Combines the flexible and scalable storage of a data lake with the relational querying semantics of a data warehouse.
OLAP Models:
- Optimized for analytical workloads.
- Pre-aggregated, allowing queries to return summaries quickly.
- Supports data aggregations across different levels, enabling drill up/down by city, individual address, etc.
Common Data Professional Roles
| Role | Responsibilities | Collaboration | Security/Privacy | Technologies/Management |
|---|---|---|---|---|
| Database Administrator | - Design, implement, maintain, and operate database systems. - Manage both on-premises and cloud-based databases. - Ensure availability and optimize performance. | - Work with stakeholders for policies and processes. - Develop backup and recovery plans. | - Manage data security. - Control user access. | N/A |
| Data Engineer | - Design and implement data workloads. - Develop ingestion pipelines and data stores. | N/A | - Ensure data privacy from on-premises to cloud. | - Utilize relational and non-relational databases. - Manage and monitor data pipelines. |
| Data Analyst | - Maximize value of data assets. - Identify trends and relationships. - Build analytical models. - Create reports and visualizations. | N/A | N/A | - Process raw data into insights. - Deliver business-relevant insights. |
Common Cloud Data Services
- Azure SQL
- Azure Database for open-source relational databases
- Azure Cosmos DB
- Azure Storage
- Azure Data Factory
- Azure Synapse Analytics
- Azure Databricks
- Azure HDInsights
- Azure Stream Analytics
- Azure Data Explorer
- Microsoft Purview
- Microsoft Fabric
Explore relational data in azure
Relational Data
Relational data structures real-world entities as tables, with rows representing instances of these entities. Each row has the same columns, but not every cell needs a value. A row in a table signifies a single instance of an entity.
Normalization
Normalization minimizes data duplication and enforces data integrity by:
- Separating each entity into its own table.
- Using unique primary keys to identify rows.
- Using foreign keys to link related entities.
For instance, customer, product, sales order, and line item entities are stored in separate tables. Primary keys uniquely identify each row, while foreign keys reference related entities. Composite keys, which are unique combinations of multiple columns, can also be used. For example LineItem table uses combination of OrderNo and ItemNo. 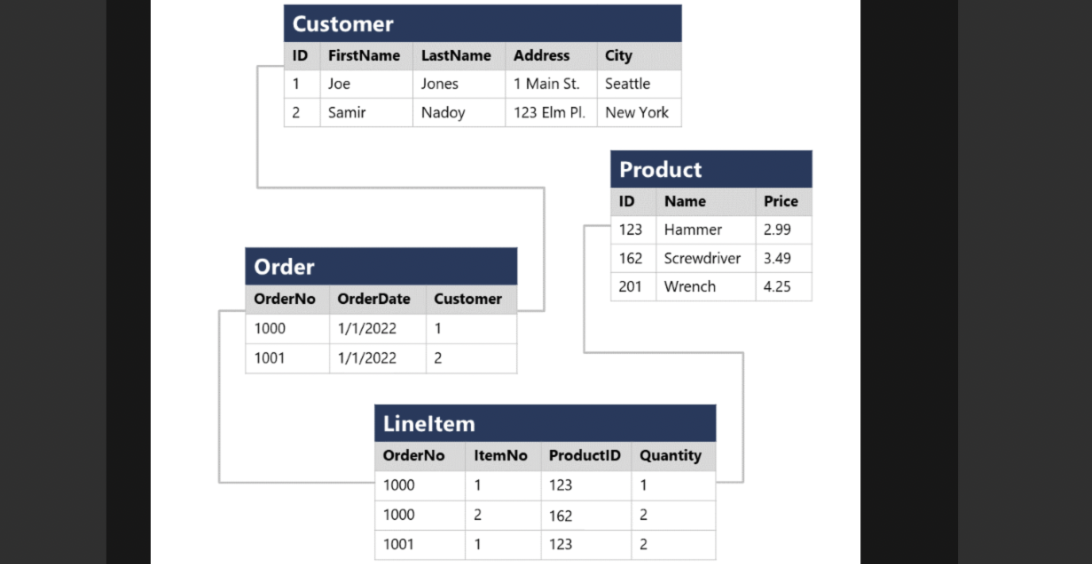
SQL (Structured Query Language)
SQL is the standard language for managing relational databases like Microsoft SQL Server, MySQL, PostgreSQL, MariaDB, and Oracle.
Key SQL Statements
SELECT, INSERT, UPDATE, DELETE, CREATE, DROP
SQL Dialects
- Transact-SQL (T-SQL): Used by Microsoft SQL Server.
- pgSQL: Used by PostgreSQL.
- PL/SQL: Used by Oracle.
SQL Statement Types
(I) DATA DEFINITION LANGUAGE (DDL)

- CREATE TABLE
CREATE TABLE Product ( ID INT PRIMARY KEY, Name VARCHAR(20) NOT NULL, Price DECIMAL NULL );
(II) DATA CONTROL LANGUAGE (DCL)
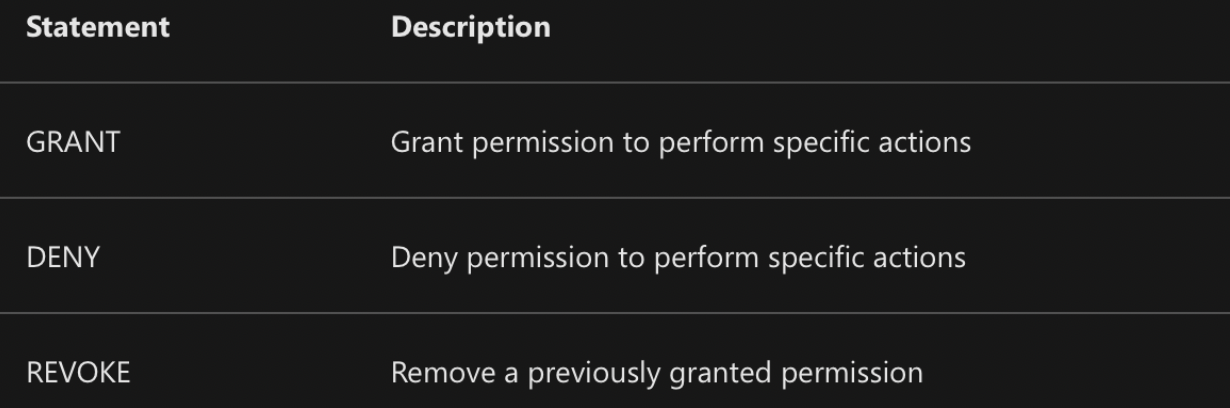
- GRANT Permissions
GRANT SELECT, INSERT, UPDATE ON Product TO user1;
(III) Data Manipulation Language (DML)
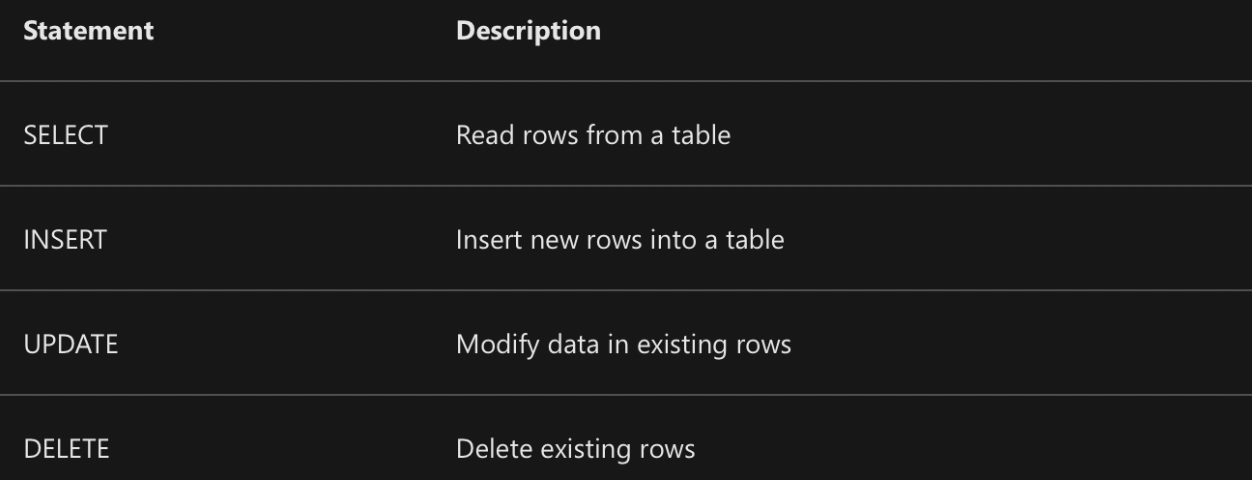
- SELECT
SELECT * FROM Customer WHERE City = 'Seattle'; - Select statement that retrieve data from multiple tables using JOIN clause. A typical join condition matches a foreign key from one table and its associated primary key in the other table.
SELECT o.OrderNo, o.OrderDate, c.Address, c.City FROM Order AS o JOIN Customer AS c ON o.Customer = c.ID - INSERT
INSERT INTO Product(ID, Name, Price) VALUES (99, 'Drill', 4.99); - UPDATE
UPDATE Customer SET Address = '123 High St.' WHERE ID = 1; - DELETE
DELETE FROM Product WHERE ID = 162;
Defining Database Objects
Views
A view is a virtual table based on a SELECT query
CREATE VIEW Deliveries AS
SELECT o.OrderNo, o.OrderDate, c.FirstName, c.LastName, c.Address, c.City
FROM Order AS o
JOIN Customer AS c ON o.Customer = c.ID;
Stored Procedures
Stored procedures encapsulate SQL statements for specific actions.
CREATE PROCEDURE RenameProduct @ProductID INT, @NewName VARCHAR(20) AS
UPDATE Product SET Name = @NewName WHERE ID = @ProductID;
Execute with:
EXEC RenameProduct 201, 'Spanner';
Indexes
An index helps to search for data in a table. When you create an index in a database, you specify a column from the table, and the index contains a copy of this data in a sorted order, with pointers to the corresponding rows in the table.
E.g. code that creates index on Name column of the Product table
CREATE INDEX idx_ProductName ON Product(Name);
Note: Indexes consume storage and can slow down insert, update, and delete operations due to maintenance overhead.